About Vance |
CALL resources main page
& Site Index |
Vance's papers and
presentations
Back to the home page of this
presentation | Forward to Tags and
Folksonomies
Blogs have several defining characteristics, such as reverse chronological listing of postings, permalinks, ability for readers to comment, ability to tag entries - one listing is given in Dieu and Stevens, 2007, and is replicated here:
Features of Social Tools and Platforms
In particular, blogs generate RSS feeds (Richardson, 2005). This is a crucial aspect of blogs. We use these feeds to efficiently locate each other's blog posts and monitor those deemed worthy of closer attention.
What is RSS? RSS is a script that describes content. When you add a posting to a blog, the script, or 'feed' from your blog is updated. If I SUBSCRIBE to your RSS feed then I can know when you update your blog. There's a cute but instructive video "RSS in very simple terms" by Lee and Sachi LeFever at http://www.commoncraft.com/rss_plain_english
![]()
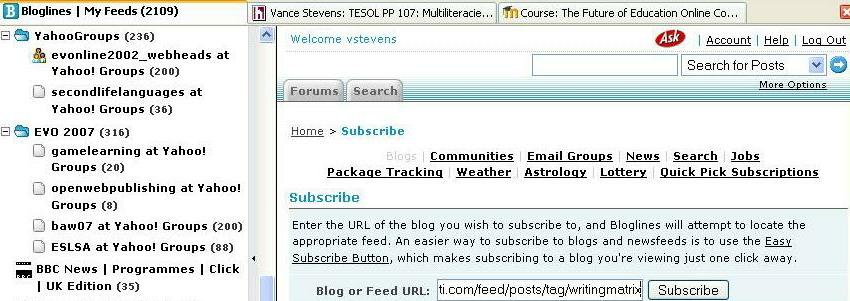
To subscribe to a feed you must locate its URL. This is usually associated with a small but obvious, usually orange, graphic on your blog site. When I enter (paste) that URL into my aggregator, such as Bloglines or Google Reader, it will tell me (by displaying the link to your blog in bold) that there is something I haven't seen yet at your blog. Since yours is just one of many blogs I follow (you could be one of my many students in my many classes) I only need to check your blog when I see that its entry is bold in my aggregator.
 |
Using a feed reader, you can subscribe to any content that generates an RSS feed. Nowadays you can find RSS or XML icons on any number of sites where content is frequently updated. Examples of such sites include output from content creation such as blogs or wikis or forums of content management systems such as Moodle or Drupal, and discussion postings in YahooGroups (where discussion on those lists has been made public). You can also subscribe to feeds of output from other aggregators themselves such as Stephen Downes's Edu_Rss or the mashups of aggregated content possible with PageFlakes (a site that itself derives its content from RSS feeds) or newsfeeds produced by MySyndicaat (see how here: http://advanceducation.blogspot.com/2007/06/preparing-to-give-series-of-lectures-in.html - Note that MySyndicaat recently reduced its free offerings to a limited set of its complete Newsmastering product). Feeds can be set up to PULL content toward you on demand using a range of sophisticated filters and other newsmastering techniques (Good (2004) Here you can see a feed to a podcast (RSS link that feeds audio content to your podcatcher like Juice or iTunes so you can put it on your MP3 player). Below there is an RSS feed to subscribe to content updates at the Drupal site http://www.webheadsinaction.org |
Coming to terms with PULL implies a mindset amenable to the paradigm shift required to transition from print literacy to multiliteracy. In the read-only century, information was distributed top down utilizing PUSH technologies. The worst impact most of us suffer from having stuff pushed at us all the time is spam in our email inboxes. However, in most workgroups, there thends to be an over-reliance on email as a the prime means of disseminating information. This means that each recipient, each node on the information distribution network, has to develop its own unique and redundant information management system to cope with the deluge. If the office is re-envisaged, then documents are stored in one place and the master updated as required, but not only that, if I update the master, I don't need to send you an email and in so doing PUSH that email out to a hundred people who don't care if the document is updated or not, increasing the deluge in their inboxes. On the contrary, I have in mind a system whereby when that document is updated, those who are interested will have subscribed to the feed that alerts them that an update is available. The only management system that each person has to master then is to be subscribed to the correct feeds (and some of that could be automated). This system is a lot more streamlined and efficient than the one where we PUSH everything out to everybody and then wonder later why some people are working off out of date versions of our documents.
Management of Information Flow and Distribution
across a Project-based Learning Network
(you know, like, a
classroom)
When I say "office" I mean here any setting where information has to be managed. An office could be a classroom of students. If I teach my students, through my example and through having them manage classroom information flow in the way that I do, then I expect that when they go to real world offices some of what they have learned will translate into the way that they manage projects they have been assigned. So I'm talking here about project management, and the projects I have in mind can be patterned on office organization, but they would also apply to management of information flow in a classroom (tracking of ongoing work and submission of final assignments), in a professional development group, or in any community of practice or collaboration project, including ones in which the teacher's purpose is to hook up writers in order to broaden the scope and enhance chances for meaningful feedback on students' writing.
The downside to this system, as was alluded to above, the one thing that people have to manage in order for the system to function, is that they have to be aware of the location of relevant content in the form of blogs or document repositories that they want or need to follow, and be subscribed to those feeds. This can be simple in case a task is well defined, but given the reality of the chaotic nature of content creation on the Web, it isn't really (or shouldn't be, for those who want to take advantage of the truly transformational power of the read-write web).
Aggregation through RSS Feeds: Pulling Distributed Knowledge to You
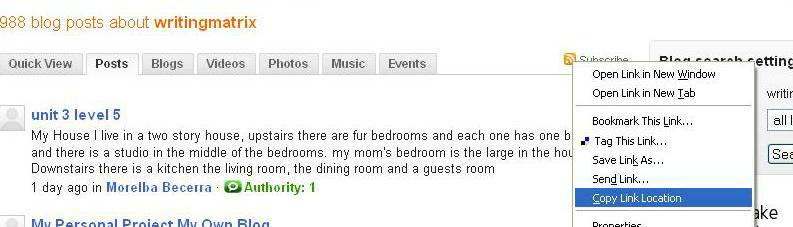
Let's take the case where I create a post and wish to know if any of my colleagues have responded. Now in the system just outlined, I might follow my colleagues' postings through their RSS feeds, and I'll become aware of what they are writing about as long as I'm checking my aggregator. But meanwhile a third person unknown to us has come on our postings and made a related posting on his or her blog we really should know about. How can we find that posting out of the thousands created in the last few seconds?
We might be able to unearth it through a normal search engine, or you could use http://blogsearch.google.com/ or http://technorati.com/ to search topics on listed blogs. There are other specialized services such as http://www.blog-search.com/ which lets you "Search for a blog, add your own blog or grab an RSS feed on the blog topic of your choice." The significance of the latter should be now be apparent if it wasn't already. Having an RSS feed of an aggregation of a specified topic is useful in that it keeps feeding results of constant updates on topic searches to your Bloglines or other aggregator. And if you want to construct your own specialized search as opposed to just "grabbing" one, and feed the results of that search via its own RSS link into your Bloglines where you can monitor it at your leisure, this is also possible with PageFlakes and MySyndicaat.
 |
However, we are still operating at the level of text found in blog postings themselves. There is a deeper layer, a meta-layer, of information that blog posts can, and should always, contain. These are called most generically TAGS but they also might be known as 'labels' or 'categories' in different Web 2.0 applications. Tags are simple in concept but the implications are difficult to describe to the uninitiated. In aggregate they comprise an organization system known as folksonomy. |
Dieu and Stevens (2007) dicuss a number of these topics in their article published in June of this year. There is much here regarding techniques associated with locating information in the blogosphere through:
I also gave a set of lectures in Spain this past summer in which I covered much of the material mentioned here. In fact much of what is set out here, and which may appear in an upcoming issue of ReCALL, is taken from the unpublished web pages created for that lecture series. You can read the three lectures in their entirety (and view the slides, and see the recordings) here: http://www.vancestevens.com/writing.htm
References
Dieu, Barbara, and Vance Stevens. (2007), Pedagogical affordances of syndication, aggregation, and mash-up of content on the Web. TESL-EJ, Volume 11, Number 1: http://tesl-ej.org/ej41/int.html
Good, Robin (Luigi Canale). (2004). The Birth Of The NewsMaster: The Network Starts To Organize Itself. MasterNewMedia from February 19, 2004; http://www.masternewmedia.org/2004/02/19/the_birth_of_the_newsmaster.htm.
Richardson, Will. (2005). RSS Quick Start Guide for Educators. Retrieved October 4, 2006 from: http://weblogg-ed.com/wp-content/uploads/2006/05/RSSFAQ4.pdf.
Back to the home page of this presentation | Forward to Tags and Folksonomies
For comments, suggestions, or further information on this page, contact Vance Stevens, page webmaster.
Copyright 2007 by Vance Stevens
under
Creative Commons License:
http://creativecommons.org/licenses/by-nc-sa/2.5/